Microarhitectura | descriere a circuitelor electrice ale unui calculator
În ingineria calculatoarelor, microarhitectura (uneori abreviată µarch sau uarch) este o descriere a circuitelor electrice ale unui calculator, ale unei unități centrale de procesare sau ale unui procesor de semnal digital care este suficientă p…
În ingineria calculatoarelor, microarhitectura (uneori abreviată µarch sau uarch) este o descriere a circuitelor electrice ale unui calculator, ale unei unități centrale de procesare sau ale unui procesor de semnal digital care este suficientă pentru a descrie complet funcționarea hardware-ului.
Cercetătorii folosesc termenul de "organizare a calculatoarelor", în timp ce oamenii din industria calculatoarelor vorbesc mai des de "microarhitectură". Microarhitectura și arhitectura setului de instrucțiuni (ISA), împreună, constituie domeniul arhitecturii calculatoarelor.
Galerie de imagini
1 Imagine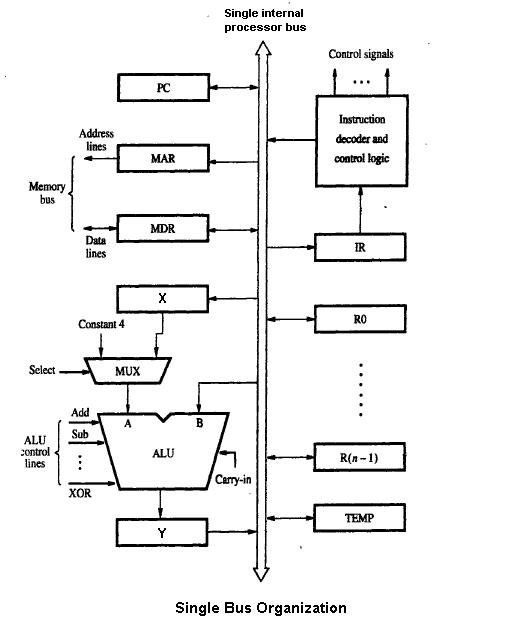
Relația cu arhitectura setului de instrucțiuni
Microarhitectura este legată de arhitectura setului de instrucțiuni, dar nu este identică cu aceasta. Arhitectura setului de instrucțiuni este apropiată de modelul de programare al unui procesor, așa cum este văzut de un programator de limbaj de asamblare sau de un compilator, care include modelul de execuție, registrele procesorului, modurile de adresare a memoriei, formatele de adrese și de date etc. Microarhitectura (sau organizarea calculatorului) este în principal o structură de nivel inferior și, prin urmare, gestionează un număr mare de detalii care sunt ascunse în modelul de programare. Aceasta descrie părțile interne ale procesorului și modul în care acestea lucrează împreună pentru a pune în aplicare specificația arhitecturală.
Elementele de microarhitectură pot fi de la porți logice simple, registre, tabele de căutare, multiplexoare, numărătoare etc., până la ALU-uri complete, FPU-uri și chiar elemente mai mari. Nivelul circuitelor electronice poate fi, la rândul său, subdivizat în detalii la nivel de tranzistor, cum ar fi ce structuri de bază de construire a porților sunt utilizate și ce tipuri de implementare logică (statică/dinamică, număr de faze etc.) sunt alese, pe lângă proiectarea logică propriu-zisă utilizată le-a construit.
Câteva puncte importante:
- O singură microarhitectură, în special dacă include microcod, poate fi utilizată pentru a implementa mai multe seturi de instrucțiuni diferite, prin modificarea memoriei de control. Totuși, acest lucru poate fi destul de complicat, chiar și atunci când este simplificat prin microcod și/sau structuri de tabele în ROM-uri sau PLA-uri.
- Două mașini pot avea aceeași microarhitectură și, prin urmare, aceeași diagramă bloc, dar implementări hardware complet diferite. Acest lucru gestionează atât nivelul circuitelor electronice, cât și, mai ales, nivelul fizic de fabricație (atât al circuitelor integrate și/sau al componentelor discrete).
- Mașinile cu microarhitecturi diferite pot avea aceeași arhitectură a setului de instrucțiuni și, prin urmare, ambele sunt capabile să execute aceleași programe. Noile microarhitecturi și/sau soluții noi de circuite, împreună cu progresele în domeniul producției de semiconductori, sunt cele care permit noilor generații de procesoare să atingă performanțe mai ridicate.
Descrieri simplificate
O descriere foarte simplificată de nivel înalt - obișnuită în marketing - poate prezenta doar caracteristici de bază, cum ar fi lățimea magistralei, împreună cu diferite tipuri de unități de execuție și alte sisteme mari, cum ar fi predicția de ramificare și memoriile cache, reprezentate ca blocuri simple - poate cu unele atribute sau caracteristici importante notate. Uneori pot fi incluse și unele detalii privind structura pipeline-ului (cum ar fi preluarea, decodificarea, atribuirea, executarea, scrierea înapoi).
Aspecte ale microarhitecturii
Ruta de date în linie este cea mai frecvent utilizată în prezent în microarhitectură. Această tehnică este utilizată în majoritatea microprocesoarelor, microcontrolerelor și DSP-urilor moderne. Arhitectura pipelined permite ca mai multe instrucțiuni să se suprapună în execuție, la fel ca o linie de asamblare. Pipeline-ul include mai multe etape diferite, care sunt fundamentale în proiectele de microarhitectură. Unele dintre aceste etape includ preluarea instrucțiunilor, decodificarea instrucțiunilor, executarea și scrierea înapoi. Unele arhitecturi includ și alte etape, cum ar fi accesul la memorie. Proiectarea conductelor este una dintre sarcinile centrale ale microarhitecturii.
Unitățile de execuție sunt, de asemenea, esențiale pentru microarhitectură. Unitățile de execuție includ unitățile logice aritmetice (ALU), unitățile de virgulă mobilă (FPU), unitățile de încărcare/stocare și predicția de ramificare. Aceste unități efectuează operațiile sau calculele procesorului. Alegerea numărului de unități de execuție, a latenței și a debitului acestora reprezintă sarcini importante de proiectare a microarhitecturii. Dimensiunea, latența, debitul și conectivitatea memoriilor din cadrul sistemului sunt, de asemenea, decizii de microarhitectură.
Deciziile de proiectare la nivel de sistem, cum ar fi includerea sau nu a unor periferice, cum ar fi controllerele de memorie, pot fi considerate ca făcând parte din procesul de proiectare microarhitecturală. Aceasta include decizii privind nivelul de performanță și conectivitatea acestor periferice.
Spre deosebire de proiectarea arhitecturală, în care obiectivul principal este un anumit nivel de performanță, proiectarea microarhitecturală acordă o atenție sporită altor constrângeri. Trebuie să se acorde atenție unor aspecte cum ar fi:
- Suprafața cipului/cost.
- Consumul de energie.
- Complexitatea logică.
- Ușurința de conectivitate.
- Fabricabilitate.
- Ușurința de depanare.
- Testabilitate.
Concepte micro-arhitecturale
În general, toate unitățile centrale de procesare, microprocesoarele cu un singur cip sau implementările multicip, execută programe prin parcurgerea următoarelor etape:
- Citiți o instrucțiune și decodificați-o.
- Găsiți toate datele asociate care sunt necesare pentru a procesa instrucțiunea.
- Prelucrați instrucțiunea.
- Scrieți rezultatele.
Complicarea acestei serii de pași aparent simple este dată de faptul că ierarhia memoriei, care include memoria cache, memoria principală și memoria nevolatilă, cum ar fi discurile dure (unde se află instrucțiunile și datele programului), a fost întotdeauna mai lentă decât procesorul în sine. Pasul (2) introduce adesea o întârziere (în termeni de procesor, adesea numită "stall") în timp ce datele sosesc pe magistrala computerului. O mare parte din cercetare a fost dedicată proiectelor care evită aceste întârzieri pe cât posibil. De-a lungul anilor, un obiectiv central al proiectării a fost acela de a executa mai multe instrucțiuni în paralel, crescând astfel viteza efectivă de execuție a unui program. Aceste eforturi au introdus structuri logice și de circuite complicate. În trecut, astfel de tehnici puteau fi implementate doar pe mainframe-uri sau supercalculatoare scumpe, din cauza cantității de circuite necesare pentru aceste tehnici. Pe măsură ce fabricarea semiconductorilor a progresat, tot mai multe dintre aceste tehnici au putut fi implementate pe un singur cip semiconductor.
Ceea ce urmează este o trecere în revistă a tehnicilor de microarhitectură care sunt comune în procesoarele moderne.
Alegerea setului de instrucțiuni
Alegerea arhitecturii setului de instrucțiuni care urmează să fie utilizată afectează în mare măsură complexitatea implementării dispozitivelor de înaltă performanță. De-a lungul anilor, proiectanții de computere au făcut tot posibilul pentru a simplifica seturile de instrucțiuni, pentru a permite implementări cu performanțe mai ridicate, economisind efortul și timpul proiectanților pentru caracteristici care îmbunătățesc performanța, în loc să le irosească pentru complexitatea setului de instrucțiuni.
Proiectarea setului de instrucțiuni a progresat de la CISC, RISC, VLIW, EPIC. Arhitecturile care se ocupă de paralelismul datelor includ SIMD și vectori.
Instrucțiuni de tip pipelining
Una dintre primele și cele mai puternice tehnici de îmbunătățire a performanței este utilizarea pipeline-ului de instrucțiuni. Primele modele de procesoare efectuau toți pașii de mai sus pe o instrucțiune înainte de a trece la următoarea. Porțiuni mari din circuitele procesorului erau lăsate inactive la orice pas; de exemplu, circuitele de decodare a instrucțiunilor erau inactive în timpul execuției și așa mai departe.
Pipeline-urile îmbunătățesc performanța permițând ca un număr de instrucțiuni să treacă prin procesor în același timp. În același exemplu de bază, procesorul ar începe să decodifice (pasul 1) o nouă instrucțiune în timp ce ultima instrucțiune așteaptă rezultatele. Acest lucru ar permite ca până la patru instrucțiuni să fie "în zbor" în același timp, ceea ce face ca procesorul să pară de patru ori mai rapid. Deși orice instrucțiune durează la fel de mult timp pentru a fi finalizată (există în continuare patru pași), procesorul ca întreg "retrage" instrucțiunile mult mai repede și poate fi rulat la o viteză de ceas mult mai mare.
Cache
Îmbunătățirile aduse la fabricarea cipurilor au permis plasarea mai multor circuite pe același cip, iar proiectanții au început să caute modalități de utilizare a acestora. Una dintre cele mai comune modalități a fost adăugarea unei cantități tot mai mari de memorie cache pe cip. Memoria cache este o memorie foarte rapidă, memorie care poate fi accesată în câteva cicluri, în comparație cu ceea ce este necesar pentru a vorbi cu memoria principală. Unitatea centrală de procesare include un controler de memorie cache care automatizează citirea și scrierea din memoria cache; dacă datele se află deja în memoria cache, acestea pur și simplu "apar", în timp ce dacă nu se află, procesorul este "blocat" în timp ce controlerul de memorie cache le citește.
Proiectele RISC au început să adauge memorie cache la mijlocul sau la sfârșitul anilor 1980, adesea cu un total de numai 4 KB. Acest număr a crescut în timp, iar în prezent, procesoarele tipice au aproximativ 512 KB, în timp ce procesoarele mai puternice vin cu 1 sau 2 sau chiar 4, 6, 8 sau 12 MB, organizați pe mai multe niveluri ale unei ierarhii de memorie. În general, mai multă memorie cache înseamnă mai multă viteză.
Antrepozitele și conductele se potriveau perfect una cu cealaltă. Anterior, nu prea avea sens să construiești o conductă care să funcționeze mai repede decât latența de acces a memoriei de tip cash off-chip. Folosind în schimb memoria cache pe cip, însemna că o conductă putea funcționa la viteza latenței de acces la memoria cache, o perioadă de timp mult mai mică. Acest lucru a permis ca frecvențele de operare ale procesoarelor să crească într-un ritm mult mai rapid decât cel al memoriei off-chip.
Predicția ramurii și execuția speculativă
Blocajele din pipeline și descărcările datorate ramificărilor sunt cele două lucruri principale care împiedică obținerea unei performanțe mai mari prin paralelismul la nivel de instrucțiuni. Din momentul în care decodificatorul de instrucțiuni al procesorului a constatat că a întâlnit o instrucțiune de ramificare condiționată și până în momentul în care poate fi citită valoarea decisivă a registrului de salt, conducta poate fi blocată timp de mai multe cicluri. În medie, fiecare a cincea instrucțiune executată este o ramificare, ceea ce reprezintă o cantitate mare de blocaj. În cazul în care ramura este executată, situația este și mai gravă, deoarece atunci toate instrucțiunile ulterioare care se aflau în pipeline trebuie să fie eliminate.
Pentru a reduce aceste penalizări de ramificare se utilizează tehnici precum predicția de ramificare și execuția speculativă. Predicția de ramificare este o metodă prin care hardware-ul face presupuneri educate cu privire la faptul că o anumită ramificare va fi efectuată. Această presupunere permite hardware-ului să pregătească instrucțiuni fără a aștepta citirea registrului. Execuția speculativă este o îmbunătățire suplimentară în care codul de-a lungul traseului prezis este executat înainte de a se ști dacă ramura trebuie să fie luată sau nu.
Execuție în afara ordinii
Adăugarea de memorii cache reduce frecvența sau durata blocajelor datorate așteptării ca datele să fie preluate din ierarhia memoriei principale, dar nu elimină complet aceste blocaje. În primele modele, o lipsă de memorie cache forța controlerul cache să blocheze procesorul și să aștepte. Desigur, în program poate exista o altă instrucțiune ale cărei date sunt disponibile în memoria cache în acel moment. Executarea în afara ordinii permite ca acea instrucțiune pregătită să fie procesată în timp ce o instrucțiune mai veche așteaptă în memoria cache, apoi reordonează rezultatele pentru a face să pară că totul s-a întâmplat în ordinea programată.
Superscalar
Chiar și cu toată complexitatea și porțile suplimentare necesare pentru a susține conceptele descrise mai sus, îmbunătățirile în domeniul producției de semiconductori au permis în curând utilizarea unui număr și mai mare de porți logice.
În schema de mai sus, procesorul procesează părți dintr-o singură instrucțiune la un moment dat. Programele de calculator ar putea fi executate mai rapid dacă mai multe instrucțiuni ar fi procesate simultan. Aceasta este ceea ce realizează procesoarele superscalare, prin replicarea unităților funcționale, cum ar fi ALU. Replicarea unităților funcționale a fost posibilă doar atunci când suprafața circuitului integrat (uneori numit "die") al unui procesor cu o singură problemă nu a mai depășit limitele a ceea ce putea fi fabricat în mod fiabil. La sfârșitul anilor 1980, au început să apară pe piață modele superscalare.
În proiectele moderne, este obișnuit să se găsească două unități de încărcare, una de stocare (multe instrucțiuni nu au rezultate de stocat), două sau mai multe unități matematice de numere întregi, două sau mai multe unități de virgulă mobilă și, adesea, un fel de unitate SIMD. Logica de emitere a instrucțiunilor devine tot mai complexă prin citirea unei liste uriașe de instrucțiuni din memorie și transmiterea lor către diferitele unități de execuție care sunt inactive în acel moment. Rezultatele sunt apoi colectate și reordonate la sfârșit.
Redenumirea registrelor
Redenumirea registrelor se referă la o tehnică utilizată pentru a evita executarea în serie inutilă a instrucțiunilor de program din cauza reutilizării acelorași registre de către aceste instrucțiuni. Să presupunem că avem două grupuri de instrucțiuni care vor utiliza același registru, un set de instrucțiuni este executat primul pentru a lăsa registrul celuilalt set, dar dacă celălalt set este atribuit unui alt registru similar, ambele seturi de instrucțiuni pot fi executate în paralel.
Multiprocesare și multithreading
Din cauza decalajului tot mai mare dintre frecvențele de funcționare a procesorului și timpii de acces la DRAM, niciuna dintre tehnicile care îmbunătățesc paralelismul la nivel de instrucțiuni (ILP) în cadrul unui program nu a putut depăși blocajele (întârzierile) lungi care apăreau atunci când datele trebuiau să fie preluate din memoria principală. În plus, numărul mare de tranzistori și frecvențele de funcționare ridicate necesare pentru tehnicile ILP mai avansate necesitau niveluri de disipare a energiei care nu mai puteau fi răcite la prețuri accesibile. Din aceste motive, noile generații de calculatoare au început să utilizeze niveluri mai ridicate de paralelism care există în afara unui singur program sau fir de program.
Această tendință este cunoscută uneori sub numele de "calcul de performanță". Această idee își are originea pe piața mainframe-urilor, unde procesarea tranzacțiilor online a pus accentul nu doar pe viteza de execuție a unei tranzacții, ci și pe capacitatea de a gestiona un număr mare de tranzacții în același timp. Având în vedere că aplicațiile bazate pe tranzacții, cum ar fi rutarea în rețea și deservirea site-urilor web, au crescut foarte mult în ultimul deceniu, industria informatică a pus din nou accentul pe problemele de capacitate și debit.
Una dintre tehnicile prin care se realizează acest paralelism este prin intermediul sistemelor multiprocesare, sisteme de calculatoare cu mai multe unități centrale de procesare. În trecut, acest lucru era rezervat pentru mainframe-urile de vârf, dar în prezent serverele multiprocesor la scară mică (2-8) au devenit un lucru obișnuit pentru piața întreprinderilor mici. Pentru marile corporații, sunt obișnuite multiprocesoarele la scară mare (16-256). Chiar și computerele personale cu mai multe unități centrale de procesare au apărut începând cu anii 1990.
Progresele în tehnologia semiconductorilor au redus dimensiunea tranzistorului; au apărut procesoarele multicore, în care mai multe procesoare sunt implementate pe același cip de siliciu. Inițial au fost utilizate în cipuri destinate piețelor integrate, unde CPU-uri mai simple și mai mici ar permite ca mai multe instanțieri să încapă pe o singură bucată de siliciu. Până în 2005, tehnologia semiconductoarelor a permis fabricarea în volum a cipurilor CMP pentru CPU-uri desktop duale high-end. Unele modele, cum ar fi UltraSPARC T1, au folosit un design mai simplu (scalar, în ordine) pentru a încadra mai multe procesoare pe o singură bucată de siliciu.
Recent, o altă tehnică care a devenit mai populară este multithreading-ul. În multithreading, atunci când procesorul trebuie să extragă date din memoria lentă a sistemului, în loc să aștepte sosirea datelor, procesorul trece la un alt program sau la un alt fir de program care este gata de execuție. Deși acest lucru nu accelerează un anumit program/fil de execuție, crește randamentul general al sistemului prin reducerea timpului de inactivitate al procesorului.
Din punct de vedere conceptual, multithreading-ul este echivalent cu o schimbare de context la nivelul sistemului de operare. Diferența constă în faptul că o unitate centrală de procesare cu mai multe fire de execuție poate efectua o schimbare de fire de execuție într-un singur ciclu de procesare, în loc de sutele sau miile de cicluri de procesare pe care le necesită în mod normal o schimbare de context. Acest lucru se realizează prin replicarea hardware-ului de stare (cum ar fi fișierul de registre și contorul de program) pentru fiecare fir activ.
O altă îmbunătățire este multithreading-ul simultan. Această tehnică permite procesoarelor superscalare să execute simultan instrucțiuni din diferite programe/thread-uri în același ciclu.
Pagini conexe
- Microprocesor
- Microcontroler
- Procesor multi-core
- Procesor de semnal digital
- Proiectare CPU
- Datapath
- paralelism la nivel de instrucțiuni (ILP)
Întrebări și răspunsuri
Î: Ce este microarhitectura?
R: Microarhitectura este o descriere a circuitelor electrice ale unui calculator, ale unei unități centrale de procesare sau ale unui procesor de semnal digital care este suficientă pentru a descrie complet funcționarea hardware-ului.
Î: Cum se referă cercetătorii la acest concept?
R: Cercetătorii folosesc termenul "organizarea calculatoarelor" atunci când se referă la microarhitectură.
Î: Cum se referă la acest concept oamenii din industria informatică?
R: Oamenii din industria informatică folosesc mai des termenul "microarhitectură" atunci când se referă la acest concept.
Î: Care sunt cele două domenii care alcătuiesc arhitectura calculatoarelor?
R: Microarhitectura și arhitectura setului de instrucțiuni (ISA) constituie împreună domeniul arhitecturii calculatoarelor.
Î: Ce înseamnă ISA?
R: ISA înseamnă Arhitectura setului de instrucțiuni.
Î: Ce înseamnă µarch? R: µArch înseamnă microarhitectură.
Articole similare
Autor
AlegsaOnline.com Microarhitectura | descriere a circuitelor electrice ale unui calculator Leandro Alegsa
URL: https://ro.alegsaonline.com/art/64586
Surse
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture